Cada cierto tiempo se nos alborota el gallinero con el tema de la AGI (artificial general intelligence, o inteligencia general artificial). Para mitigar el nivel de ansiedad y evitar sobresaltos innecesarios os refiero a la siguiente competición que ha sido específicamente diseñada para medir capacidades de inteligencia general:
ARC Prize
1.000.000 $ en premios que se repartirán cuando se consiga resolver el 85 % de los problemas del conjunto de validación. Esto es lo que Taleb llama “put the skin in the game”.
El conjunto de validación lo componen puzzles basados en imágenes en las que a partir de dos ejemplos hay que razonar como completarías un tercer caso. Están diseñados de manera que no midan solamente habilidades sino la adquisición de las mismas. Aquí se demuestra la capacidad de generalización que va más allá de un razonamiento puramente memorístico. Estos problemas pueden ser resueltos por la mayoría de los humanos.
La mente pensante detrás de esta iniciativa es François Chollet. La definición que maneja de AGI es la siguiente:
Una AGI es un sistema que puede adquirir nuevas habilidades de manera eficiente fuera de sus datos de entrenamiento y resolver problemas de carácter abierto.
Esto significa que es un sistema capaz de adaptarse a un nuevo entorno que no ha visto antes y que sus creadores (desarrolladores) no habían anticipado. Me parece una formalización bastante razonable de lo que es un AGI.
Es importante tener en cuenta que resolver este concurso es una condición necesaria pero no suficiente para conseguir un AGI. Eso sí, estaríamos ante un nuevo cambio de paradigma que supondría, sin lugar a dudas, un paso enorme en el camino de tener máquinas dotadas de razonamiento general.
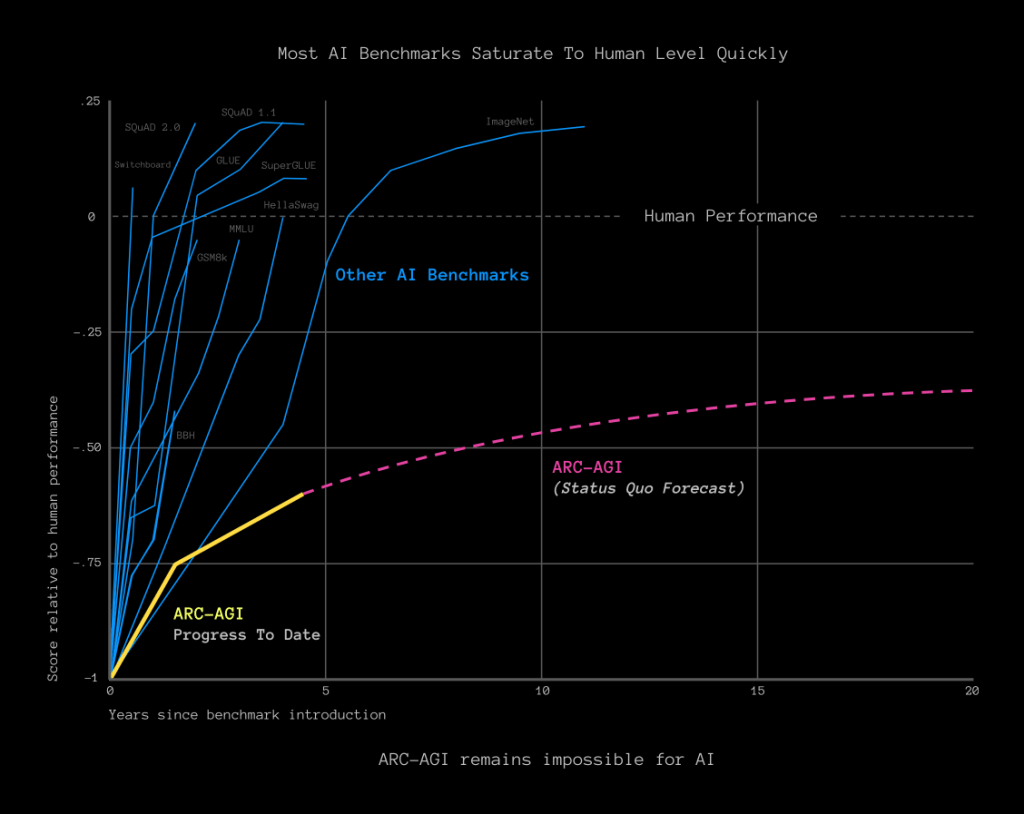
Para entender qué supone medir el progreso de los modelos con el conjunto de validación de ARC, podéis ver en la figura se muestra el rendimiento de distintos modelos sobre otros conjuntos de evaluación frente ARC. Mientras que en los conjuntos orientados a tareas, los modelos presentan un rendimiento similar o superior al humano, en ARC orientado a AGI están muy por debajo y su rendimiento, presumiblemente, satura.
Para terminar, en el caso del nuevo modelo o1 representa un buen avance respecto a GPT-4o, con la mejor versión (o1 preview) logrando estar a la par con Claude 3.5, lo cual es logro notable ya que utiliza menos recursos optimizando la reutilización de patrones de razonamiento conocidos.
